Daten schneller verarbeiten mit verbesserter In-Memory OLTP Funktion
Mission-critical performance im SQL Server 2016
Daten in-memory zu verarbeiten, bedeutet, die Geschwindigkeit für eine breitgefächerte Menge an Szenarien dramatisch zu steigern. Die Funktion wurde erstmals im SQL Server 2014 eingeführt und für den SQL Server 2016 deutlich weiterentwickelt.
Dazu bietet der SQL Server das In-Memory Online Transaction Processing (OLTP) als einen Bestandteil des In-Memory-Toolsets an, welches hauptsächlich in transaktionalen Anwendungsszenarien Verwendung findet.

SQL Server 2016 – Everything built in. OLTP ist ein Teil des neuen SQL Servers. Quelle: Used with permission from Microsoft.
Als ein wesentliches Merkmal wird die In-Memory-Technologie für den SQL Server als built into beworben – es sind also keine zusätzlichen Programme oder Programmiermodelle notwendig. Microsoft bringt es auf den Punkt: „It is still SQL Server!“.
Die Verbesserungen sollen bei Lese-Vorgängen einen Faktor zwischen 10 und 100 erreichen und bei Schreib-Vorgängen einen Faktor von bis zu 30.
Realisiert werden soll diese Verbesserung durch die bereits genannte In-Memory-OLTP und die Verwendung von nativen stored procedures und memory-optimized tables.
In-memory OLTP ist eine speicher-optimierte Datenbank-Engine, die in die normale SQL Server-Engine integriert ist. Das wesentliche Merkmal stellen hier sperr- und verzögerungsfreie Datenstrukturen sowie die Unterstützung einer extrem hohen Anzahl von konkurrierenden Datenzugriffen dar. Dadurch kann die Schreibrate in transaktionalen Anwendungsszenarien massiv erhöht werden.
Für die Verbesserung der Leserate besteht die Funktion stored procedures in nativen Code zu kompilieren (Visual C) und auf memory-optimized tables anzuwenden. Denn native Kompilation erlaubt einen schnelleren Zugriff auf Daten und einen effizienteren Ausführungsplan als zur Laufzeit interpretiertes T-SQL. Native stored procedures allein erreichen aber noch nicht die angekündigte dramatische Leistungssteigerung. Hier kommen die memory-optimized tables ins Spiel.
Laut den verfügbaren White Papers besteht der Hauptunterschied einer speicher-optimierten Tabelle und einer normalen Tabelle in der Tatsache, dass in einer speicher-optimierten Tabelle die Daten nicht mehr in Seiten sondern in Zeilen gespeichert werden. Änderungen werden in sogenannten Checkpoint-Dateien, also Daten und Delta-Datei-Paarungen, als speicher-optimierte Dateigruppen gespeichert. Vergleichbar mit normalen Tabellen, mit dem Unterschied, dass diese nur append-only sind, um Engpässe bei Lese-/Schreibvorgängen der Hardware zu minimieren.
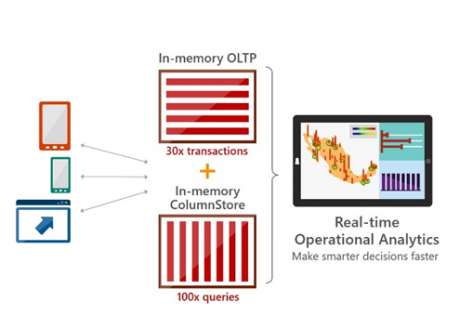
Das In-Memory-OLTP sowie der In-Memory-Column-Store verbessern die Geschwindigkeit drastisch. Quelle: Used with permission from Microsoft.
Um den angekündigten Geschwindigkeitsschub realisieren zu können, arbeitet der SQL Server mit zwei Arten von memory-optimized tables: zum einen den beständigen oder SCHEMA_AND_DATA-Tabellen und zum anderen den nicht-beständigen oder SCHEMA_ONLY-Tabellen. Beständige Tabellen werden wie der Name es vermuten lässt, vollständig geloggt und persistiert, so dass diese nach einem Server-Neustart noch verfügbar sind. Bei nicht-beständigen Tabellen wird nur das Schema persistiert. Die Daten hingegen existieren nur zur Laufzeit des SQL Servers und werden in Szenarien eingesetzt, in denen das Wiederherstellen von Daten nicht notwendig ist, zum Beispiel zum Speichern von Session-Daten einer Webanwendung.
Als eine Neuerung im SQL Server 2016 werden nun auch ALTER-TABLE-Befehle auf memory-optimized tables für Index- oder Schema-Änderungen unterstützt. Im SQL Server 2014 mussten diese hierfür noch gelöscht und neu erstellt werden.
Die Verwendung von Indizes in memory-optimized tables wird nicht nur unterstützt, sondern ist ein fester Bestandteil einer memory-optimized table, da diese Tabellen über mindestens einen Index verfügen müssen. Für SCHEMA_AND_DATA-Tabellen gilt sogar, dass ein einzigartiger Index definiert werden muss, um Datensätze während einer Neuerstellung einer Tabelle aus den Transaktionslogs zu identifizieren. Für die Erstellung von Indizes stehen zwei Arten von Nonclustered-Indizes zur Verfügung: Hash- und Range-Indizes. Hash-Indizes sind optimal für Vergleichssuchen, während Range-Indizes auf Bereichsabfragen oder geordnete Datenabrufe optimiert sind. Die Besonderheit: Indizes für memory-optimized tables existieren ausschließlich im Speicher. Sie werden weder in Checkpoint-Dateien gespeichert, noch werden Änderungen an ihnen in Index-Logs erfasst.
Zusammenfassend verspricht Microsoft durch die Verwendung von memory-optimized tables, native stored procedures sowie einer zusätzlichen Datenbank-Engine eine dramatische Verbesserung der Leistung des SQL Servers. Wie auch Sie diese dramatische Leistungsverbesserung bei sich anwenden können, lesen Sie bald in einem How-To-Artikel.
Geschrieben von Tino Krüger